mysql分表(水平分表和垂直分表)
一、水平分表
数据有很多的时候,存储在多张表里面;这些表的表结构肯定是一模一样的。
表结构一模一样的表,在存储数据的时候,我们就可以理解成水平分表!
数据有1000W的时候,我们进行水平分表;分成2张表;
策略一:前500W数据,分在表1里面;后500W数据,分在表2里面;
策略二:id是单数的,分在表1里面;id是双数的,分在表2里面。
完成策略一:首先1000W的数据;新增数据。
读取曾经的数据,跑前500W在表1里面;跑后500W在表2里面;
新增数据:需要一直维护一个id值,通过id值去判断,我们的数据应该存储在那张表里面了。假如1001W,这个时候就存储在表3里面;到达1501W,这个时候就存储在表4里面。
查询数据的时候:
查询数据的,我们必需给我们的数据维护好id值,查询的时候,尽量使用id查询,通过id值,就能区分它在哪一个表里面了!
merge引擎;它可以把myisam引擎的多张表连接起来,你查询的时候,直接查询这张表,它就会把所有的myisam引擎的表,都遍历一次,这样就获得了我们的数据。
非myisam引擎的表,就要使用中件间(第三方工具)实现同merge引擎一样的效果!
完成策略二:首先1000W的数据;新增数据。
读取曾经的数据,跑数据id,id是单数的就存储在表1里面;跑数据id,id是双数的就存储在表2里面。
新增数据:需要一直维护一个id值,通过id值去判断, 只要id是单数就存储在表1里面;id是双数就存储在表2里面。
策略二,修改成5张表的时候:完成它的方式就是取余!
面试常考:有一个用户信息表,数据量有点大了,我们要进行分表,应该怎么划分!
令旺:性别;志强:籍贯;晓红:id;徐飞:年龄。
用户信息表:
1)新用户注册的时候,注册信息
2)用户登录的时候,登录获得信息
用户信息表,经常都是回答使用用户名进行划分的。
用户名是一个字符串,可以通过hash转成整型,整型在进行取余就可以了。
要拿的值,一定是尽量是唯一的,不要重复的,不可修改的。
新日任务:完成策略二!
分表的数据先定义好:2张表;
分表的算法要定义好:id进行取余
通过算法,就会发现表名可以设计的有点意思:
id = 3;
3 % 2 = 1;
id = 4;
4 % 2 = 0;
值,只有0或者是1;
确定一个表前缀,然后加上这个取余的结果,就可以组装成表名!
表前缀是:goods_ ; 取余结果:0 ;组装 :goods_0(表名)
1)创建好二张表:
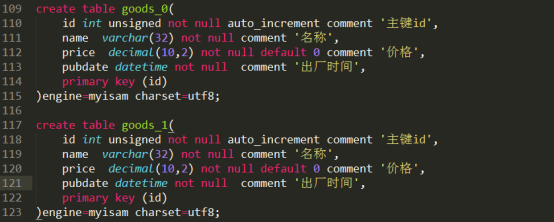
2)维护id的表:这个id一定要是自增长的!

插入数据:
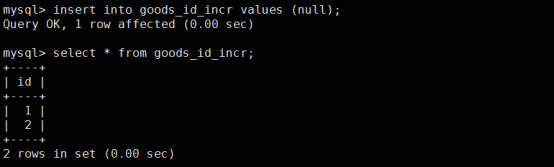
我们让这个表的id一直增长上去,把这个增长的id取出来,做为我们的id来判断就可以了。
3)代码实现:
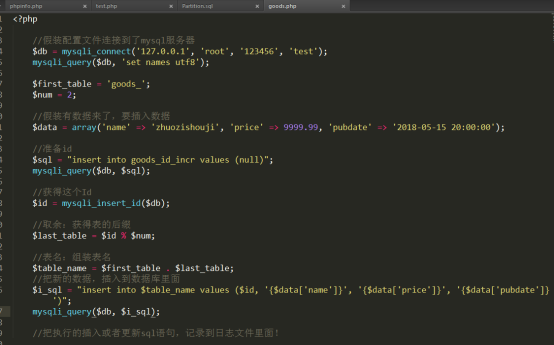
访问几次:
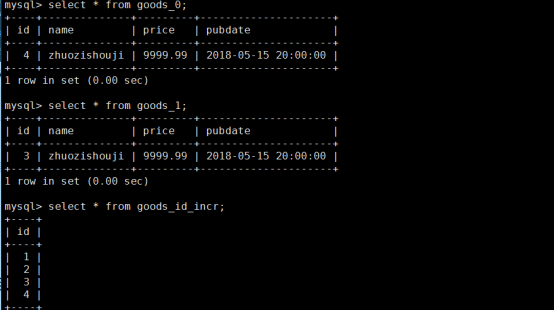
查看数据库的情况:
4)发现一个问题:goods_id_incr
表的数据是4条;以后会是多少条?
这些数据,只是在组装id的时候,有用。之后都将没有作用。所以我们应该清空它!
delete from goods_id_incr;:清空表数据,不清空自动增长!
truncate goods_id_incr : 清空表数据,并且把自动增长清空,所有不能使用它。
二、垂直分表
表里面有很多字段,有一些是常用的,有一些是不常用的。
把常用的分成一张表,把不常用的分成一张表。
假如:用户表
id name age sex phone email wechat address content …..
常用的:
id name age sex phone email wechat
不常用的:
id fid address content …..
补充说明:垂直分表的真实内涵
我们的数据是存储到硬盘里面的,那么一行数据的内容都是存储在一起的。而IO一次性读取的数据,也是整块读取的。当io读取一次的时候,里面有很多数据,是不需要的。这次读取就浪费太多资源。
进行垂直分表。那一行数据里面,都是需要的。现在IO一次性读取出来的内容,都是需要的。